
In this article, we will look at the Synthetic Data Vault – A Framework to generate Synthetic Data.
Introduction
The Synthetic Data Vault (SDV) is a library ecosystem that allows users to rapidly study single-table, multi-table, and timeseries datasets in order to produce new Synthetic Data with the same structure and statistical attributes as the original dataset.
When training Machine Learning models, synthetic data may be used to complement, augment, and in some circumstances replace actual data. Furthermore, it allows for the testing of Machine Learning or other data-dependent software systems without the danger of data leakage.
Under the shell, it employs a number of probabilistic graphical modelling and deep learning-based algorithms. We use novel hierarchical generative modelling and recursive sampling approaches to provide a wide range of data storage architectures.
SDV-generated synthetic data can be utilized as supplementary information while training Machine Learning models (data augmentation). It can even be used in place of the original data at times because they are both identical. It also preserves the original data integrity, i.e., the actual data is not shown to the user when seeing its synthetic form. SDV generates data using recursive sampling methods and hierarchical models, allowing for a variety of structures to be used to store the synthetic data.
Features and Functionalities:
- Single-table synthetic data generators having the following characteristics:
- Copulas and Deep Learning-based models are used.
- Multiple data types and missing data are handled with minimal user input.
- Predefined and custom constraints, as well as data validation, are supported.
- Synthetic data generators having the following characteristics for complicated, multi-table, relational datasets:
- Metadata for whole multi-table datasets is defined using a bespoke and extensible JSON format.
- Copulas and recursive modelling approaches are used.
- Synthetic data generators having the following characteristics for multi-type, multi-variate timeseries datasets:
- Statistical, Autoregressive, and Deep Learning models are used.
- Conditional sampling is based on contextual factors.
- Metrics for Evaluating Synthetic Data, such as:
- With a single line of code, an easy-to-use Evaluation Framework can assess the quality of your synthetic data.
- Metrics for many data modalities, such as Single Table Metrics and Multi Table Metrics.
- A benchmarking framework for comparing several synthetic data generators, such as:
- Dozens of datasets from various data modalities are already ready to be run on.
- Tools for adding additional synthetic data generators and datasets quickly.
- Distributed computing is used to shorten computation times.
- Comprehensive results are offered in a variety of leaderboard forms.
Implementation
Here’s an example of utilizing Synthetic Data Vault to implement the Hierarchical Modelling Algorithm (HMA) for producing fresh data. Recursive scanning of a relational dataset is possible using HMA. It employs a tabular model, which allows it to learn correlations between distinct variables across all tables in the dataset.
- Import the sdv library
- Import the sdv.demo module’s load demo() function to load the relational demo data.

- Loading the Relational Data

With the’metadata’ argument set to ‘True,’ the result of load data() will be a tuple containing an instance of the dataset’s metadata and a dictionary containing data tables imported in the form of Pandas DataFrames.

- Display the metadata and the dictionary of tables
- Visualize the metadata in order to know the relationships between the data tables.

Each of the three tables’ main and foreign keys are depicted in the output figure. It also indicates the parent-child relationships between them, for example, ‘transactions’ is a child of’sessions’, which is a child of ‘users’.
- Import the HMA1 class of sdv.relational module.

- By giving the metadata of relational datasets as a parameter, you may instantiate the HMA class.

- Fit the HMA model to the data in the relational tables.

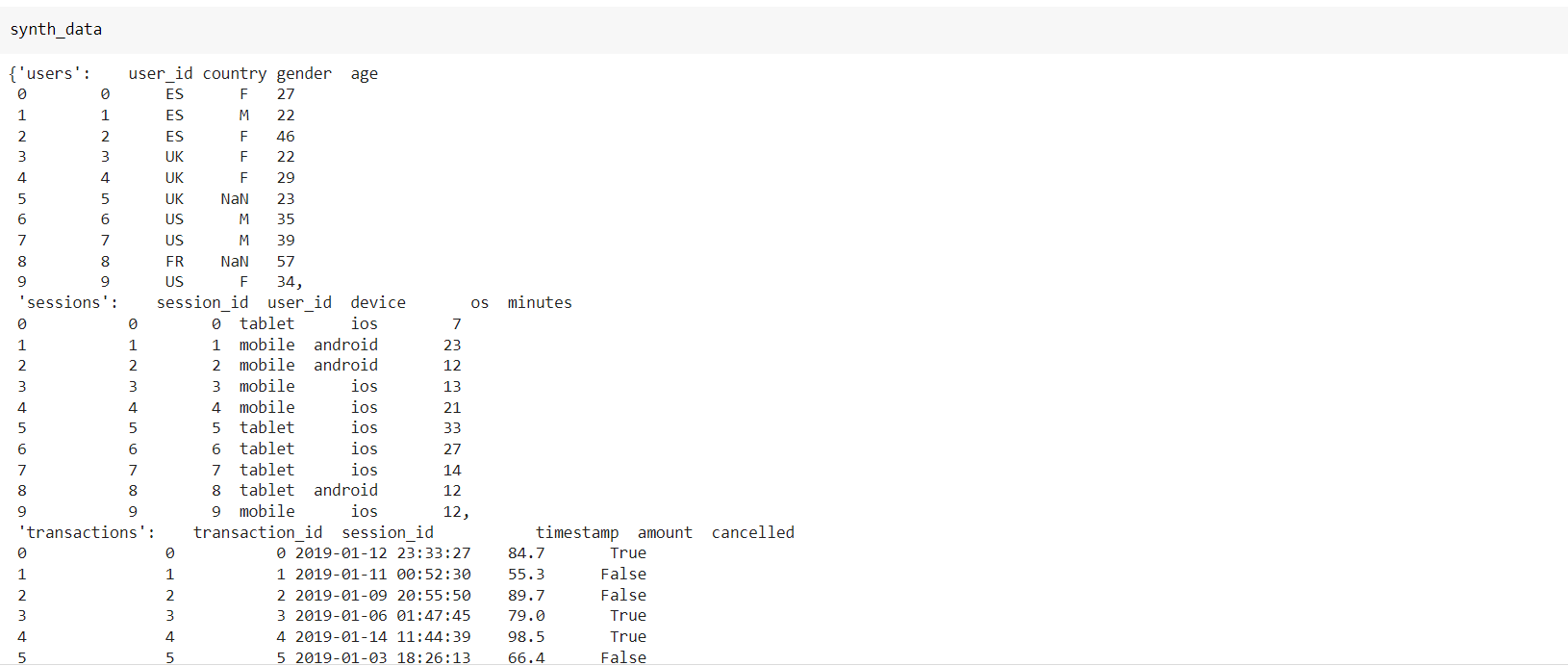
- Synthesize new data from the HMA model.

There will be a new dictionary of tables similar to those in the original ‘tb’ dictionary. The tables will have new data that is identical to the old relational tables.
- Save the HMA model and then load the saved model.

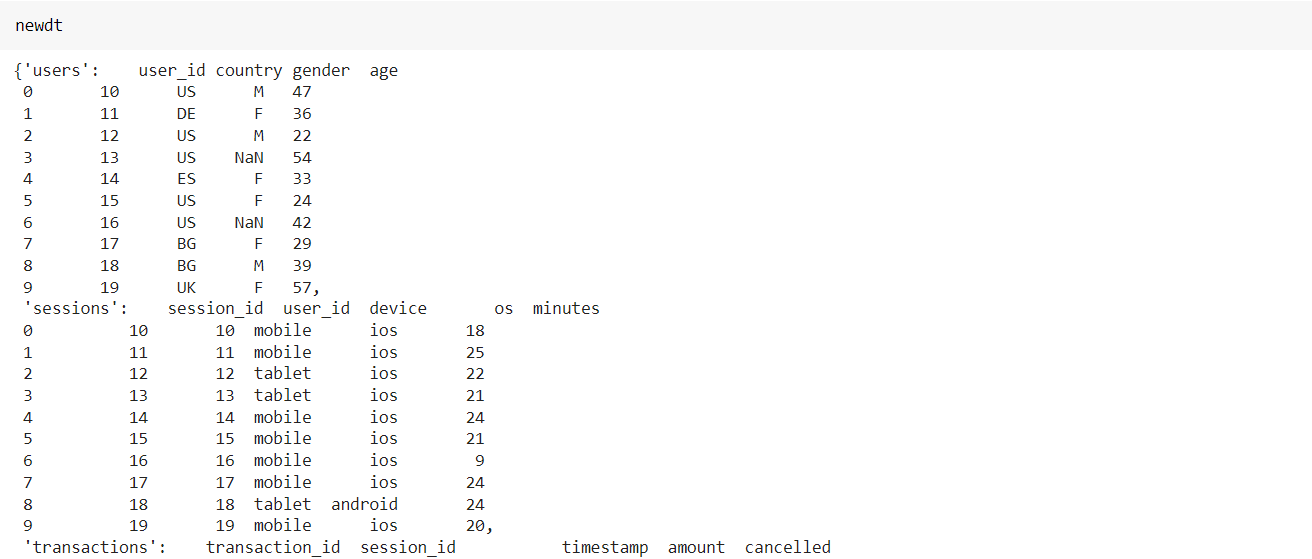
- Sample the newly synthesized data from the “load_model” instance.

- Display the synthetic Data.

Sandeep Kumar is the Founder & CEO of Aitude, a leading AI tools, research, and tutorial platform dedicated to empowering learners, researchers, and innovators. Under his leadership, Aitude has become a go-to resource for those seeking the latest in artificial intelligence, machine learning, computer vision, and development strategies.






