
This tutorial explains solving regression problems using a neural network approach instead of using Supervised Machine Learning Algorithm. You’ll be able to solve simple regression problems at the end of this tutorial.
We’ll use Jupyter Notebook to write the code and TensorFlow as our machine learning framework. Our guide about TensorFlow Architecture will help you to understand its working architecture.
In this Tutorial:
- Setup Notebook
- Load Dataset
- Data Preprocessing
- Build Model
- Train Model
- Make Prediction
Setup Notebook
Use Setup Kaggle Notebook guide to create a notebook on kaggle.com and give it a name Simple Linear Regression Using Neural Network and Add Simple Linear Regression dataset to the project.
So we’ll do all the coding in this notebook. You can remove the default code and add the required libraries to be used in this project.
import tensorflow as tf
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_splitLoad Data
We have added the Simple Linear Regression dataset in the previous step. Use the below code to load the data from the CSV file to the pandas data frame and show the top 5 rows from the data frame.
housing_data_df = pd.read_csv('../input/simple-linear-regression/kc_house_data.csv')
housing_data_df.head()
Data Preprocessing
In this problem, we’re estimating House Price based on various properties of the house. e.g number of bedrooms, bathrooms, sqft area, etc. So the Price column is our target column and rest are features to be used in the training process.
features = housing_data_df[['bedrooms','bathrooms','sqft_living','sqft_lot','floors','yr_built']]
target = housing_data_df[['price']]Though we’re using bedrooms, bathrooms, sqft_living,sqft_lot, floors, and yr_build columns as main features. You can try with different columns in your experiment.
And then split the datasets into training and test dataset using the train_test_split method.
train_features,test_features,train_target,test_target = train_test_split(features,target)So train_features and train_target will be used in the training process and test_features and test_target will be used for prediction and evaluation purposes.
Build Model
We’ll use the Sequential model with two dense layers, and one output layer that returns a value, House Price.
no_features_columns = len(train_features.keys())
no_target_columns = 1
model = tf.keras.models.Sequential([
tf.keras.layers.Dense(32,activation='relu',input_shape=[no_features_columns]),
tf.keras.layers.Dense(16,activation='relu'),
tf.keras.layers.Dense(no_target_columns)
])And then compile the model.
model.compile(optimizer=tf.keras.optimizers.RMSprop(),
loss='mean_squared_error',
metrics=['mean_squared_error'])Train Model
Train the model for 10 epoch using train_features and train_target.
history = model.fit(train_features,train_target,epochs=10)And you will see each iteration log with mean_squared_error values.
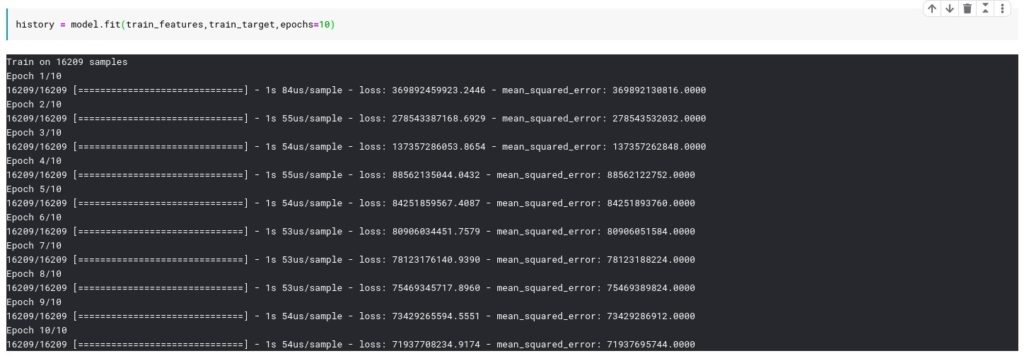
As you noted, mean_squared_error is very high because our model is not optimized. We use hyper optimization tunning techniques to solve this issue but this is out of the scope for this tutorial.
Make Prediction
To test our trained model, we’ll use the test dataset which is unseen data for the model. And create a data frame to compare predicted values with the actual values and show the top 10 results.
test_predictions = model.predict(test_features).flatten()
results_df = pd.DataFrame({'Predicted Price': test_predictions,'Actual Price':test_target.values.flatten()})
results_df.head(10)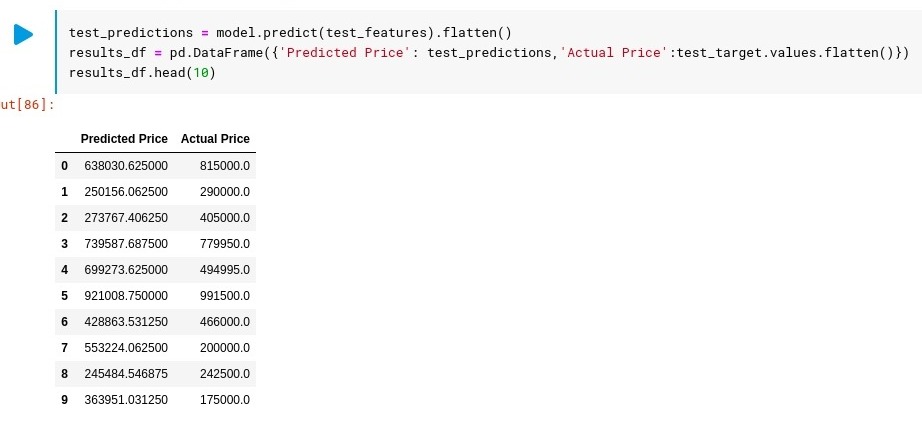
So this tutorial explained the build process for simple neural network using TensorFlow to solve a regression problem.

Sandeep Kumar is the Founder & CEO of Aitude, a leading AI tools, research, and tutorial platform dedicated to empowering learners, researchers, and innovators. Under his leadership, Aitude has become a go-to resource for those seeking the latest in artificial intelligence, machine learning, computer vision, and development strategies.





