
Researchers and data scientists are employing synthetic data to create new products, improve machine learning model performance, substitute sensitive data, and save money on data acquisition expenditures. In this article, we will see how to generate synthetic tabular data using GANs.
What is CTGAN?
CTGAN learns from original data and generates extremely realistic tabular data using multiple GAN-based algorithms. We will utilize Conditional Generative Adversarial Networks from the open-source Python modules CTGAN and Synthetic Data Vault to generate synthetic tabular data (SDV). Data scientists may use the SDV to learn and build data sets from single tables, relational data, and time series. It is a one-stop shop for all types of tabular data.
Let’s look at how to use the CTGAN class from SDV to learn a dataset and then produce synthetic data with the same format and statistical features.
To begin, we will import one of our demo datasets, student placements, which contains information about MBA students who applied for placements in 2020.
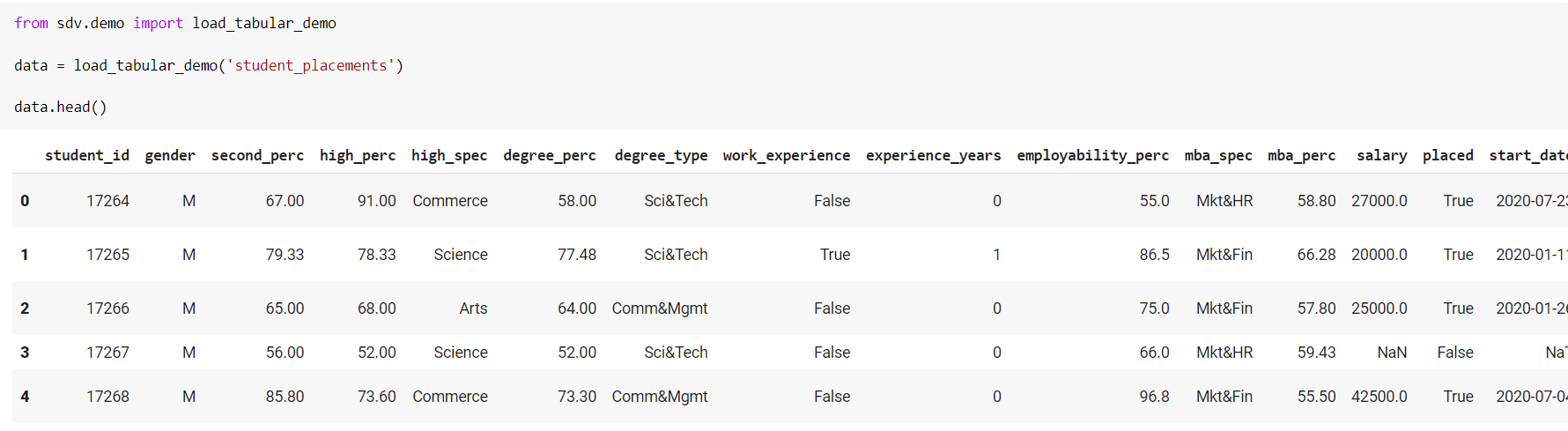
Let us use CTGAN to learn this data, and then sample synthetic data from fresh students to assess how well the model captures the above-mentioned properties. You will need to perform the following to do this:
- Create an instance of the sdv.tabular.CTGAN class by importing it.
- Pass our table to its fit technique.
- Invoke its sample method, passing in the number of synthetic rows you want to produce.

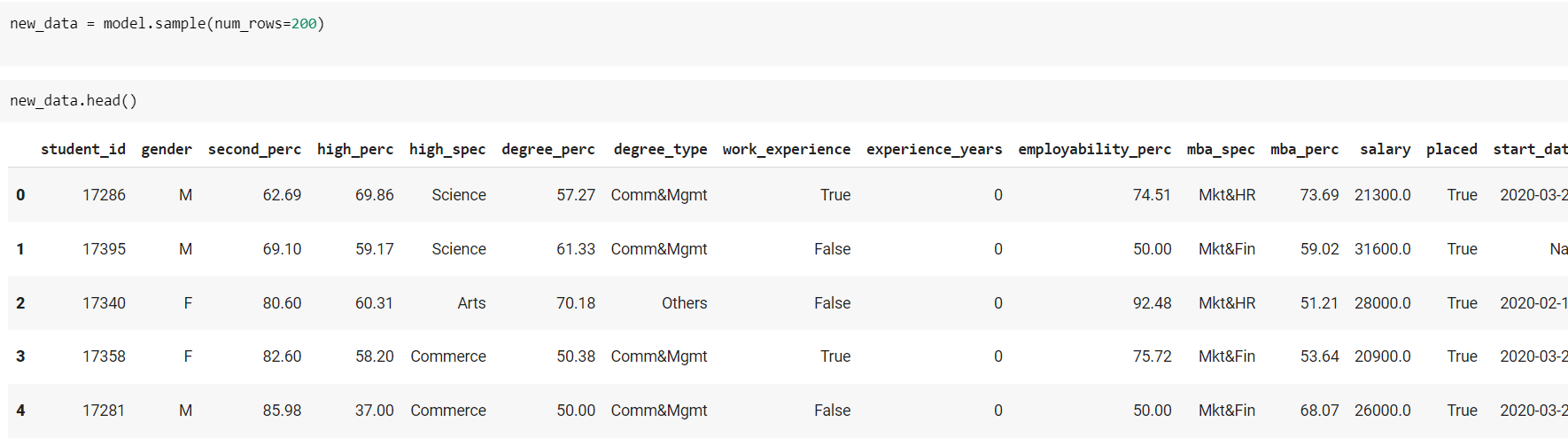
Generating synthetic data from the model
Once the modelling is complete, you can produce additional synthetic data by using the sample function from your model and specifying the number of rows to generate. A necessary argument is the number of rows (num rows).
Model saving and loading
In many cases, generating synthetic versions of your data directly in systems that do not have access to the original data source will be more convenient. For instance, suppose you want to produce testing data on the fly within a testing environment that does not have access to your production database. Fitting the model with real data every time you need to produce fresh data is not possible in these cases, thus you will need to fit a model in your production environment, save the fitted model into a file, send this file to the testing environment, and then load it there to sample from it.
After you’ve fitted the model, just use its save function, specifying the name of the file into which you wish to save the model. The filename extension is unimportant, but we will use the .pkl extension to indicate that the serialization protocol used is pickle.

This will have resulted in the creation of a file called my model.pkl in the same directory where you are executing SDV.
Load the data and generate new Data
The file you just created may be delivered to the system that will generate the synthetic data. Once there, you may load it with the CTGAN.load method and then sample new data from the loaded instance:

Specifying the Primary Key of the table
One of the first things you may have noticed when looking at the example data is that there is a student id column that serves as the table’s primary key and is expected to contain unique values. Indeed, when we look at the number of times each value appears, we can see that they all appear at most once:

However, when we examine the synthetic data that we created, we see that certain numbers occur more than once:
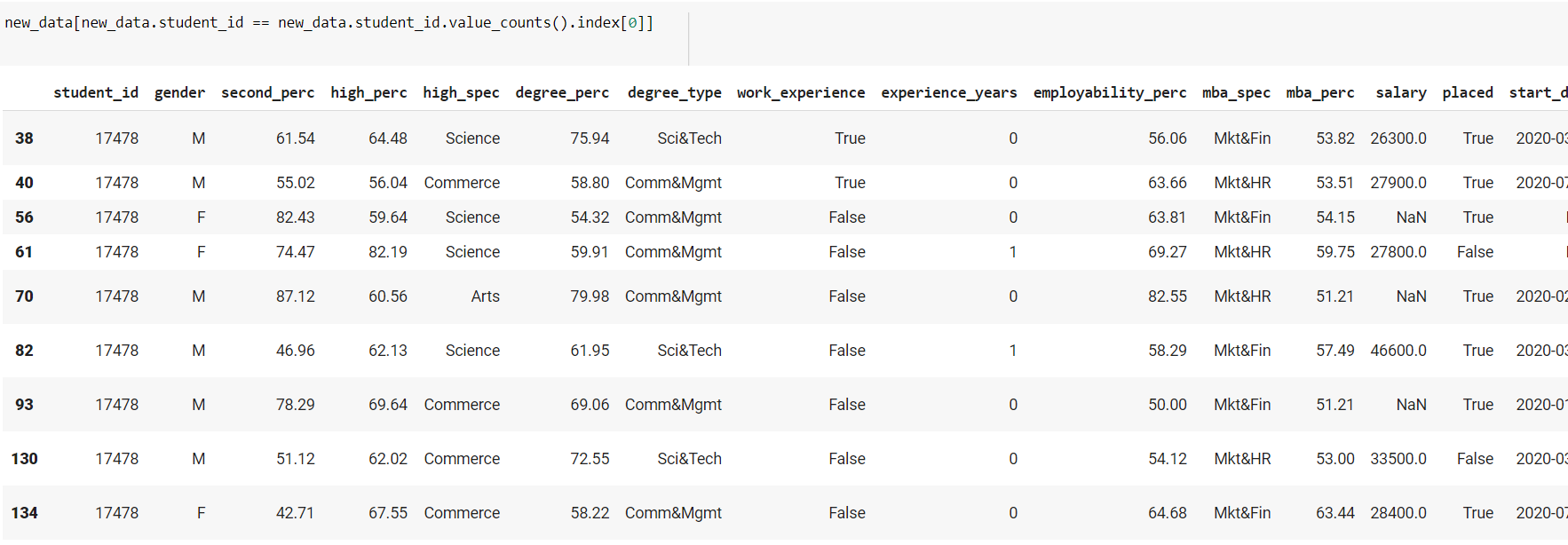
This occurs because the model was never informed that the student id has to be unique, therefore when it creates fresh data, it will cause collisions sooner or later. To address this, we may supply the option primary key to our model when we construct it, giving the name of the column that serves as the table’s index.

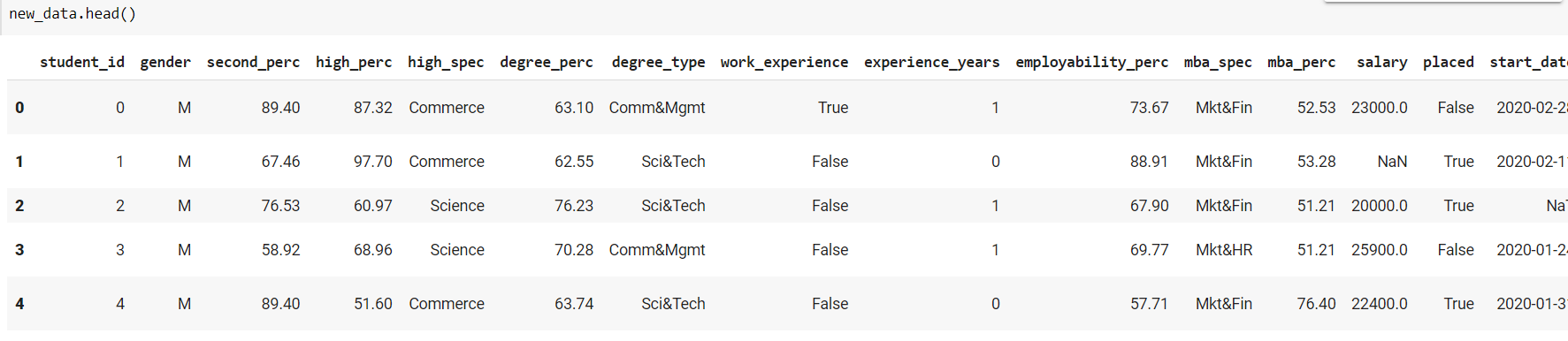
As a consequence, the model will discover that this column must be distinct and will create a distinct series of values for the column:


Sandeep Kumar is the Founder & CEO of Aitude, a leading AI tools, research, and tutorial platform dedicated to empowering learners, researchers, and innovators. Under his leadership, Aitude has become a go-to resource for those seeking the latest in artificial intelligence, machine learning, computer vision, and development strategies.






