
What are Support Vector Machines?
SVM is a Supervised Machine Learning Algorithm which solves both the Regression problems and Classification problems. SVM finds a hyperplane that segregates the labeled dataset(Supervised Machine Learning) into two classes.
Support Vectors
These data points are closest to the hyperplane. These are the critical elements. Since removing them may alter the position of the dividing hyperplane.
Hyperplane
The hyperplane is a line which linearly divides and classifies the data. When we add the new testing data, whatever side of the hyperplane it goes will eventually decide the class that we assign to it.
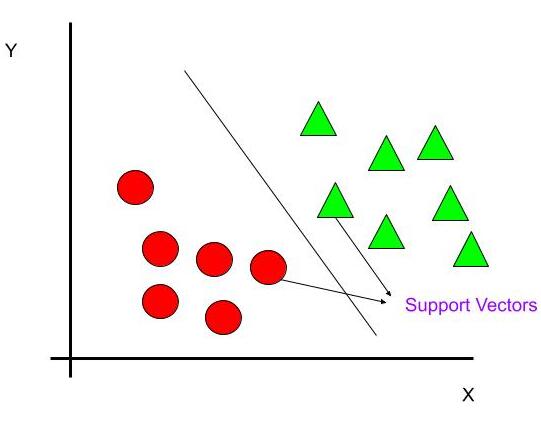
How to find the right Hyperplane(Linear Data)
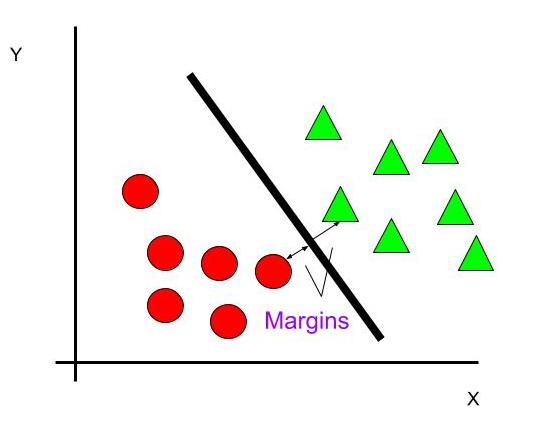
To segregate the dataset into classes we need the hyperplane. To choose the right hyperplane we need margin. Margin is the distance between the hyperplane and the closest point from either set.
To select the right hyperplane we choose hyperplane which has a maximum possible margin between the hyperplane and any point within the dataset. Therefore this gives a fair chance to classify new data correctly.
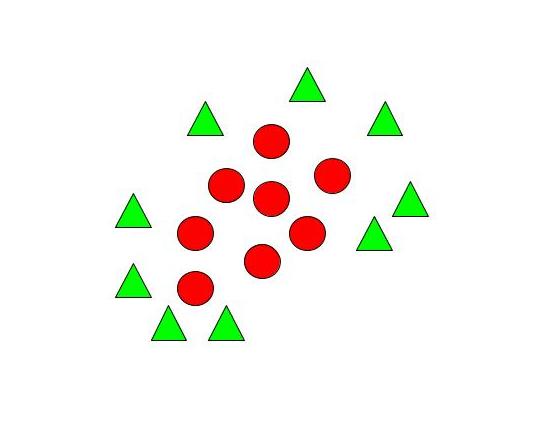
How to segregate Non – Linear Data?

When we can easily separate data with hyperplane by drawing a straight line is Linear SVM. When we cannot separate data with a straight line we use Non – Linear SVM. In this, we have Kernel functions. They transform non-linear spaces into linear spaces. It transforms data into another dimension so that the data can be classified.
It transforms two variables x and y into three variables along with z. Therefore, the data have plotted from 2-D space to 3-D space. Now we can easily classify the data by drawing the best hyperplane between them.
Linear SVM vs Non-Linear SVM
| Linear SVM | Non-Linear SVM |
|---|---|
| It can be easily separated with a linear line. | It cannot be easily separated with a linear line. |
| Data is classified with the help of hyperplane. | We use Kernels to make non-separable data into separable data. |
| Data can be easily classified by drawing a straight line. | We map data into high dimensional space to classify. |
Advantages of SVM
- Good for smaller cleaner datasets.
- Accurate results.
- Useful for both linearly separable data and non – linearly separable data.
- Effective in high dimensional spaces.
Disadvantages of SVM
- Not suitable for large datasets, as the training time can be too much.
- Not so effective on a dataset with overlapping classes.
- Picking the right kernel can be computationally intensive.
Applications of SVM
- Sentiment analysis.
- Spam Detection.
- Handwritten digit recognition.
- Image recognition challenges

Sandeep Kumar is the Founder & CEO of Aitude, a leading AI tools, research, and tutorial platform dedicated to empowering learners, researchers, and innovators. Under his leadership, Aitude has become a go-to resource for those seeking the latest in artificial intelligence, machine learning, computer vision, and development strategies.






