AI is only as valuable as its ability to run reliably, at scale, in production. But most organizations don’t get that far.
- What Role Does DevOps Actually Play in AI Projects?
- 1. CI/CD for ML: Automating Model and Data Integration
- 2. IaC: Creating Scalable, Reproducible AI Environments
- 3. Containerization and Orchestration: Making Models Portable
- 4. Monitoring, Drift Detection, and Feedback Loops
- 5. GitOps and Workflow Management
- How DevOps Certification Courses Close the Gap
- How Organizations Benefit from Upskilling Teams in DevOps for AI
- Conclusion
Over 87% of AI models fail to reach production. And among those that do, many stumble after deployment. They break under real-world data, behave inconsistently, or become too complex to maintain without constant firefighting.
At the core of these failures is not flawed modeling. It’s a lack of operational readiness. Building a high-performing model is only half the job. Getting it to work consistently in a live environment is where most teams fall short.
Deploying AI presents a different kind of challenge. Models evolve. Data shifts. Infrastructure must adapt to changes in scale, latency, and architecture. Yet, many AI teams still rely on fragile scripts, disconnected tools, and manual workflows that don’t hold up in production.
This is where DevOps makes the difference, not just as a theory but as a practical discipline.
AI teams need the ability to manage environments, automate pipelines, monitor performance, and respond quickly to drift or failure. These are DevOps capabilities applied in an AI context.
Scaling AI doesn’t come from smarter models alone. It comes from teams trained in DevOps principles, which can build reproducible workflows, deploy consistently, and operate AI systems with the same discipline as software applications.
In this blog, we’ll explore how DevOps helps teams move from experimental AI to reliable, enterprise-scale deployment.
What Role Does DevOps Actually Play in AI Projects?
To work reliably in production, AI requires robust infrastructure, automation, and lifecycle management, all areas where DevOps makes a critical impact.
In traditional software, DevOps brings consistency and speed to deployments. AI plays an even broader role in helping teams manage complex workflows, evolving models, and dynamic data environments.
Let’s look at how DevOps principles directly support scalable AI systems.
1. CI/CD for ML: Automating Model and Data Integration
AI development doesn’t stop once a model is trained. Models need to be tested, deployed, retrained, and rolled back just like any other software component.
CI/CD (Continuous Integration and Continuous Deployment) for ML helps automate this cycle:
- CI ensures new model versions are tested with fresh data and code changes
- CD safely promotes models through staging and production without manual intervention
Use case: A recommendation engine retrained weekly based on user behavior. With CI/CD, retraining, testing, and deployment happen automatically, reducing delays and errors.
2. IaC: Creating Scalable, Reproducible AI Environments
AI systems often rely on GPUs, scalable compute, and specialized libraries.
IaC (Infrastructure as Code) lets teams define and manage this infrastructure as version-controlled code.
Tools like Terraform or Ansible help:
- Provision GPU-enabled environments reproducibly
- Ensure consistent dev, test, and prod configurations
- Auto-scale resources for model training or serving
Before IaC: Weeks of manual environment setup
After IaC: Reusable templates deploy full AI stacks in minutes
3. Containerization and Orchestration: Making Models Portable
AI models often fail in production because of inconsistent environments.
Docker solves this by packaging everything, including code, libraries, and runtime, into one portable container.
Kubernetes, in turn, orchestrates and scales these containers to:
- Serve models in real-time or batch
- Restart failed services automatically
- Optimize resource allocation
Use case: An NLP model is containerized, deployed via Kubernetes, and scaled based on incoming API traffic.
4. Monitoring, Drift Detection, and Feedback Loops
Deploying a model is not the finish line; it’s the beginning of continuous oversight.
DevOps practices add critical observability:
- Monitoring tracks model latency, failures, and infrastructure metrics
- Drift detection alerts when live data diverges from training data
- Feedback loops allow retraining or rollback when performance degrades
Use case: A fraud detection model degrades silently. With drift detection and alerts, the team proactively avoids business impact.
5. GitOps and Workflow Management
AI projects involve constant changes to code, data, and model logic.
GitOps applies Git-based versioning to entire ML workflows.
This allows:
- Clear history of pipeline, model, and infra changes
- Automated rollbacks if a model fails in production
- Better collaboration between data science and engineering
Use case: A model update fails in production. GitOps enables instant rollback to the last stable version with full traceability.
DevOps plays a crucial role in making AI workflows reproducible, scalable, and maintainable. But having the right tools isn’t enough; what truly matters is knowing how to use them effectively.
That’s why DevOps skills have become essential for teams working with AI. And increasingly, DevOps certification courses are helping organizations build the expertise needed to operationalize AI at scale. It’s no longer just about deploying models; it’s about doing so reliably, repeatedly, and with confidence.
How DevOps Certification Courses Close the Gap
DevOps certification courses equip engineers with the ability to apply industry-grade tooling with discipline and at scale. It’s not just about knowing the tool; it’s about knowing when and how to use it, especially in complex AI workflows.
Here’s what certified professionals are typically prepared to handle:
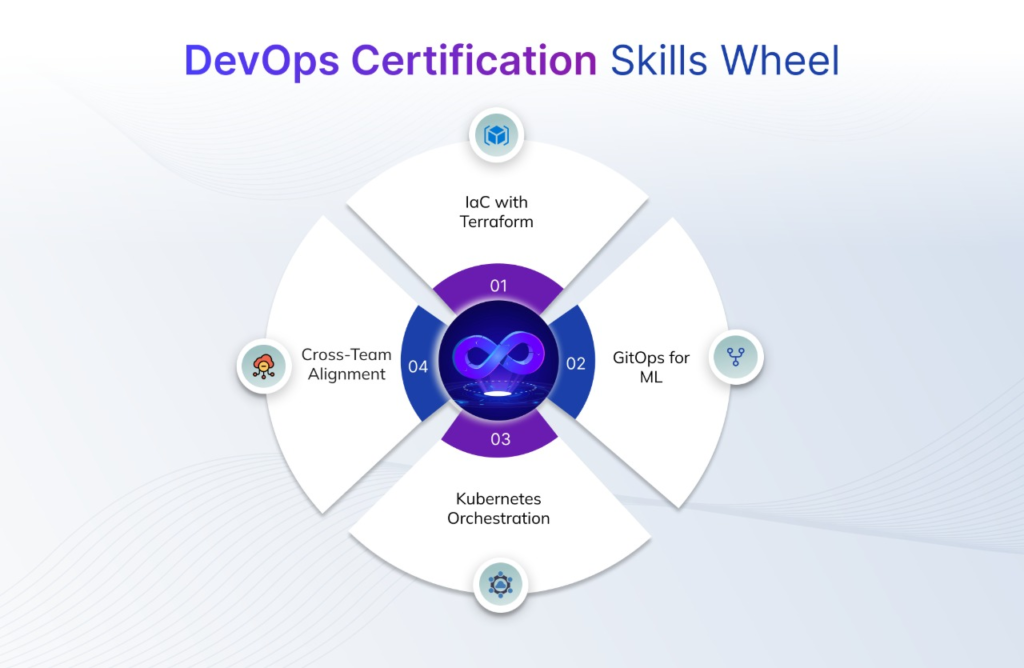
1. Terraform for Infrastructure as Code (IaC)
Through certification, teams learn to use Terraform and similar IaC tools to:
- Provision cloud/GPU infrastructure on demand
- Reproduce environments across dev, staging, and production
- Minimize misconfigurations and setup delays
Before IaC: Engineers spend days replicating infrastructure manually.
After IaC: One script, multiple environments stable and scalable.
2. GitOps for Versioned ML Workflows
GitOps practices, heavily emphasized in DevOps certifications, enable:
- Full version control of model artifacts, pipelines, and configurations
- Automated rollbacks if a model fails post-deployment
- Transparent handoffs between data scientists and operations teams
Without GitOps, AI updates happen through ad hoc changes that are difficult to track and harder to undo.
3. Kubernetes for Model Orchestration
Certified engineers know how to deploy AI models on Kubernetes clusters that:
- Automatically scale with demand
- Maintain high availability through self-healing
- Support versioned deployments for controlled rollouts
Without certification: Teams often rely on manual deployment scripts that don’t scale, are brittle, and introduce risk with every update.
4. Cloud-Native Pipelines and Security-First Deployments
Most DevOps certification tracks now include modules on:
- Building CI/CD pipelines for ML workflows in AWS, Azure, or GCP
- Deploying models as APIs, batch jobs, or streaming services
- Embedding security and compliance into deployment flows
Certified professionals reduce the risk of model outages or compliance gaps by building pipelines that are both fast and secure.
Certification Builds More Than Tool Skills
The real value of certification is consistency.
Certified engineers follow best practices that prevent technical debt, siloed knowledge, and ad hoc deployments.
They also help create a shared operational language across roles, bridging the gap between data science, engineering, and infrastructure teams.
What This Means for AI Projects
When teams lack DevOps fluency, even the best models end up stuck in pilot mode.
But when DevOps practices are embedded through certified talent, AI becomes easier to deploy, easier to monitor, and easier to scale.
Organizations gain the ability to:
- Deploy models faster and more reliably
- Respond to failure with less disruption
- Extend AI systems across departments without reinventing infrastructure
This is why DevOps certification isn’t just a personal credential; it’s a team enabler.
It turns knowledge into systems and experimentation into execution.
How Organizations Benefit from Upskilling Teams in DevOps for AI
Many organizations are investing heavily in AI but struggle to operationalize it.
The issue isn’t the models. It’s the inability to reliably move from development to production and keep models running at scale.
This isn’t a failure of data science. It’s a gap in operational readiness. By upskilling internal teams in DevOps practices, organizations lay the groundwork for AI systems that are stable, scalable, and sustainable.
A clear understanding of the DevOps career path can help teams build the right skills to support this shift from siloed experimentation to full-scale AI deployment.
- Faster Time to Market
AI projects often get stuck in the transition from prototype to product.
Manual processes, unstable environments, and unclear handoffs slow down progress and increase friction across teams.
DevOps-trained teams solve this by automating deployments, standardizing workflows, and spinning up environments in minutes, not days.
Outcome: AI models ship faster, updates roll out smoothly, and teams iterate more often.
- Fewer Failures, Faster Recovery
Speed is only useful if systems are reliable.
Without DevOps foundations, AI systems often fail silently or degrade in performance. Rollbacks are messy, and incidents become costly distractions.
Upskilled teams introduce version control, real-time monitoring, and automated rollback mechanisms that make production systems resilient by design.
Outcome: Fewer incidents, shorter downtimes, and more reliable AI systems.
- Scalable Systems, Not Just One-Off Fixes
Once reliability is in place, organizations face their next challenge scale. More models. More data. More teams.
DevOps capabilities make it possible to build shared infrastructure that supports diverse use cases without reinventing the wheel every time. Pipelines become reusable. Resources are predictable. Compliance becomes manageable.
Outcome: AI grows from isolated experiments to scalable, enterprise-ready platforms.
- Stronger Collaboration Between Roles
Scaling AI isn’t just technical; it’s cross-functional.
AI initiatives often stall because of misalignment: data scientists push models, infra teams scramble to support them, and developers build temporary fixes to hold it all together.
Upskilling solves this by creating a shared language between functions. When everyone
Understands how models are deployed, monitored, and governed, the handoffs become smoother and the outcomes more consistent.
Outcome: Clearer roles, faster alignment, and stronger delivery across the AI lifecycle.
- Upskilling Is a Smarter Investment
It’s tempting to hire your way out of the DevOps gap. But relying on a few external experts often leads to bottlenecks and knowledge silos.
Upskilling your existing teams distributes critical skills, preserves domain context, and builds long-term resilience into your AI capability.
The result: Self-sufficient teams that scale with your business and don’t break when key people leave.
Conclusion
By now, one thing should be clear: building an AI model is no longer the hard part.
Getting that model into production, keeping it stable, and scaling it across the organization is where the real challenge begins.
The organizations succeeding with AI today aren’t just investing in algorithms.
They’re investing in operational excellence in teams that understand versioning, automation, observability, and lifecycle management as core to the AI stack.
DevOps certification plays a critical role in that transformation.
It brings consistency across workflows, closes execution gaps, and equips teams to deliver AI systems that work reliably in the real world.
If your goal is to move beyond pilots and build AI that performs at scale, the next step is clear: Upskill your teams with the right DevOps training from a provider who understands the demands of production-grade AI.
Because in the future of AI, it’s not the smartest model that wins; it’s the most scalable system.
And that system starts with the people who know how to run it.

Sandeep Kumar is the Founder & CEO of Aitude, a leading AI tools, research, and tutorial platform dedicated to empowering learners, researchers, and innovators. Under his leadership, Aitude has become a go-to resource for those seeking the latest in artificial intelligence, machine learning, computer vision, and development strategies.