If you run a content-heavy WordPress site, showing related or similar posts at the end of every article is one of the easiest ways to boost user engagement and internal linking.
But doing this manually—matching keywords or tags—is time-consuming and inaccurate.
- Why Traditional Keyword Matching Falls Short
- What Are Embeddings?
- Step-by-Step Approach to Find Similar Posts
- Step 1: Install Libraries and Set Up Logging
- Step 2: Fetch All Posts from WordPress
- Step 3: Clean Post Content
- Step 4: Find Similar Posts with Cosine Similarity
- Step 5: Main Execution and Output
- Understanding the Output
- Final Thoughts
With AI and semantic similarity, you can automate this entire process.
In this guide, we’ll build a simple AI-powered Colab notebook that finds the 3 most similar posts for any given WordPress article using Sentence Transformers and FAISS.
Why Traditional Keyword Matching Falls Short
Before we dive into the solution, let’s understand the problem.
Traditional search engines rely on keyword matching. If your post about “WordPress performance optimization” uses different terminology than another post about “speeding up WordPress sites,” they might not be connected—even though they’re clearly related.
This is where semantic search shines. It understands that:
- “WordPress speed” ≈ “WordPress performance”
- “Optimization techniques” ≈ “Speed improvement methods”
- “Slow loading times” ≈ “Performance issues”
Semantic search captures the intent and meaning behind content, not just surface-level word matches.
What Are Embeddings?
Think of embeddings as converting text into a language that computers can understand and compare—like turning words into mathematical coordinates in space.
Here’s a simple analogy: Imagine plotting words on a map where similar concepts are close together:
- “Dog” and “puppy” would be near each other
- “WordPress” and “website” would be neighbors
- “Security” and “hacking” would be in the same neighborhood
Sentence transformers take this concept further by converting entire sentences, paragraphs, or documents into these mathematical representations (called vectors). Similar content ends up with similar vectors, making it easy to find related articles.
Step-by-Step Approach to Find Similar Posts
We’ll build a Python script that runs in Google Colab or any Python environment to find the top three similar posts for a given post ID. Here’s the process:
- Install Libraries: Set up the tools needed for fetching, processing, and analyzing posts.
- Fetch Posts from WordPress: Use the WordPress REST API to get all posts.
- Clean Post Content: Remove HTML and irrelevant text to focus on meaningful content.
- Generate Embeddings: Convert text into embeddings using Sentence Transformers.
- Find Similar Posts: Use FAISS and cosine similarity to identify the top three matches.
- Output Results: Display the results in a clean JSON format.
Let’s dive into each step with code and explanations!
Step 1: Install Libraries and Set Up Logging
To get started, we need libraries to fetch posts (requests), clean HTML (beautifulsoup4), create embeddings (sentence-transformers), and perform similarity searches (faiss-cpu). We also set up logging to track progress and debug issues.
# Install required libraries
!pip install requests beautifulsoup4 sentence-transformers faiss-cpu
import requests
import logging
from bs4 import BeautifulSoup
import re
from sentence_transformers import SentenceTransformer
import faiss
import numpy as np
import json
# Set up logging for debugging
logging.basicConfig(level=logging.INFO)What’s Happening:
- Libraries: requests fetches data from the WordPress API, BeautifulSoup cleans HTML, sentence-transformers generates embeddings, and faiss-cpu handles fast similarity searches.
- Logging: Logs messages to help diagnose issues, like missing posts or API errors.
- SEO Tip: Using modern tools like Sentence Transformers makes your site cutting-edge, appealing to tech-savvy readers searching for “AI-powered WordPress recommendations.”
Step 2: Fetch All Posts from WordPress
We’ll fetch all posts from your WordPress site using the REST API (e.g., https://your-site.com/wp-json/wp/v2/posts). The function handles pagination to ensure we get every post, even if there are hundreds, and gracefully manages errors like invalid page numbers.
def fetch_posts(wp_api_url: str, per_page: int = 100, status: str = "publish") -> list[dict]:
all_posts = []
page = 1
headers = {
'User-Agent': 'Python Requests/WordPress Similar Posts Script'
}
try:
wp_api_url = wp_api_url.rstrip('/') + '/posts'
while True:
url = f"{wp_api_url}?per_page={per_page}&page={page}&status={status}"
logging.info(f"Fetching URL: {url}")
response = requests.get(url, headers=headers, timeout=10)
if response.status_code == 400 and "rest_post_invalid_page_number" in response.text:
logging.info(f"Page {page} is beyond available pages; stopping pagination")
break
response.raise_for_status()
posts = response.json()
if not posts:
logging.info("No more posts to fetch; stopping pagination")
break
all_posts.extend(posts)
logging.info(f"Fetched {len(posts)} posts from page {page}")
page += 1
logging.info(f"Total fetched: {len(all_posts)} posts from {wp_api_url}")
return all_posts
except requests.RequestException as e:
logging.error(f"Error fetching posts: {e}")
if 'response' in locals():
logging.error(f"Response details: {response.text}")
logging.info(f"Returning {len(all_posts)} posts fetched before error")
return all_postsWhat’s Happening:
- API Call: Fetches posts in batches of 100 (per_page=100) to balance speed and API limits.
- Pagination: Loops until no more posts are returned or an invalid page error occurs, ensuring all posts are fetched.
- Error Handling: Catches errors like the previous rest_post_invalid_page_number (page 3 was invalid) and returns any posts fetched before the error.
- Authentication: Includes a placeholder for API tokens if your site requires it.
- SEO Tip: Fetching all posts ensures comprehensive recommendations, boosting internal linking for terms like “WordPress related posts.”
Step 3: Clean Post Content
Raw post content from WordPress includes HTML tags, scripts, and boilerplate text (e.g., “share this post”). We clean it to focus on meaningful text for accurate embeddings.
def clean_html_content(html_text: str) -> str:
if not html_text or not isinstance(html_text, str):
logging.warning("Empty or invalid HTML content")
return ''
try:
soup = BeautifulSoup(html_text, 'html.parser')
for element in soup(['script', 'style', 'nav', 'footer', 'header', 'aside', 'form', 'button', 'blockquote', 'figcaption']):
element.decompose()
text = soup.get_text(separator=' ', strip=True)
text = re.sub(r'\s+', ' ', text).strip()
boilerplate_phrases = [
'share this post', 'related posts', 'subscribe now', 'leave a comment',
'posted in', 'tagged with', 'previous post', 'next post', 'by', 'read more'
]
pattern = r'\b(' + '|'.join(re.escape(p) for p in boilerplate_phrases) + r')\b\.?\s*'
text = re.sub(pattern, '', text, flags=re.IGNORECASE)
cleaned_text = re.sub(r'\s+', ' ', text).strip()
if not cleaned_text:
logging.warning("Cleaned content is empty")
return cleaned_text
except Exception as e:
logging.error(f"Error cleaning HTML content: {e}")
return html_textWhat’s Happening:
- HTML Removal: Strips tags like <script>, <style>, and navigation elements using BeautifulSoup.
- Boilerplate Removal: Deletes common phrases like “share this post” to focus on core content.
- Flexibility: You can modify this to use the post’s title or first paragraph instead (more on this later).
- SEO Tip: Clean content ensures accurate semantic analysis, improving the relevance of recommendations for “WordPress content similarity.”
Step 4: Find Similar Posts with Cosine Similarity
This function converts the query post’s content into an embedding, compares it to other posts using FAISS, and finds the top three similar posts based on cosine similarity.
def find_similar_posts(query_content: str, current_post_id: str, post_data: list, index, k: int = 3,
min_distance: float = 0.1, max_distance: float = 0.8) -> list[dict]:
model = SentenceTransformer('all-MiniLM-L6-v2')
query_embedding = model.encode([query_content], convert_to_numpy=True, normalize_embeddings=True)
scores, indices = index.search(query_embedding, min(k + 10, len(post_data)))
distances = 1 - scores # Convert cosine similarity to distance (1 - similarity)
logging.info(f"Raw distances for post ID {current_post_id}: {distances[0][:min(k+10, len(post_data))]}")
logging.info(f"Corresponding post IDs: {[post_data[idx]['id'] for idx in indices[0] if idx < len(post_data)]}")
similar_posts = []
for i, idx in enumerate(indices[0]):
if idx >= len(post_data):
logging.warning(f"Index {idx} out of range")
continue
post_id = post_data[idx]['id']
distance = float(distances[0][i])
if post_id == current_post_id:
logging.info(f"Skipping self-link for post ID {post_id} (distance: {distance:.4f})")
continue
if distance < min_distance or distance > max_distance:
logging.info(f"Skipping post ID {post_id} with distance {distance:.4f} (outside {min_distance}-{max_distance})")
continue
similar_posts.append({
'linked_post': post_data[idx]['title'],
'linked_post_id': post_id,
'distance': distance
})
logging.info(f"Added post ID {post_id} with distance {distance:.4f}")
if len(similar_posts) == k:
break
logging.info(f"Found {len(similar_posts)} similar posts for post ID {current_post_id}")
return similar_postsWhat’s Happening:
- Embeddings: The all-MiniLM-L6-v2 model converts text into 384-dimensional embeddings.
- FAISS Index: Uses IndexFlatIP for cosine similarity, where distance = 1 – similarity.
- Filtering: Skips the query post itself and posts outside the distance range (0.1–0.8) to ensure relevance.
- SEO Tip: Cosine similarity delivers precise recommendations, aligning with search terms like “semantic post recommendations.”
Step 5: Main Execution and Output
This segment ties everything together: fetches posts, processes them, builds the FAISS index, and finds similar posts for the specified post ID.
# Main execution
wp_api_url = 'https://yourblog.com/wp-json/wp/v2' # Replace with your WordPress API URL
posts = fetch_posts(wp_api_url, per_page=100, status='publish')
# Process posts
post_data = []
for idx, post in enumerate(posts):
post_id = str(post.get('id', 'unknown'))
post_title = post.get('title', {}).get('rendered', '').strip()
post_content = post.get('content', {}).get('rendered', '').strip()
if not post_title or not post_content or post_id == 'unknown':
logging.warning(f"Skipping post ID {post_id}: Missing title, content, or ID.")
continue
# Use full content (default), title, or first paragraph
cleaned_content = clean_html_content(post_content)
# Alternative: Use title
# cleaned_content = post_title
# Alternative: Use first paragraph
# soup = BeautifulSoup(post_content, 'html.parser')
# first_p = soup.find('p')
# cleaned_content = clean_html_content(str(first_p)) if first_p else ''
if not cleaned_content:
logging.warning(f"Skipping post ID {post_id}: No valid content after cleaning.")
continue
post_data.append({
'id': post_id,
'title': post_title,
'content': cleaned_content
})
logging.info(f"Processed {len(post_data)} valid posts.")
logging.info(f"Valid post IDs: {[post['id'] for post in post_data]}")
# Generate embeddings and FAISS index
if post_data:
model = SentenceTransformer('all-MiniLM-L6-v2')
contents = [post['content'] for post in post_data]
embeddings = model.encode(contents, convert_to_numpy=True, batch_size=32, normalize_embeddings=True)
dimension = embeddings.shape[1]
index = faiss.IndexFlatIP(dimension) # IndexFlatIP for cosine similarity
index.add(embeddings)
logging.info(f"Created FAISS index with {len(contents)} embeddings.")
else:
logging.error("No valid posts to process.")
index = None
# Find similar posts for a specific post ID
query_post_id = '64363' # Replace with your post ID
result = {}
if index:
found_query = False
for post in post_data:
if post['id'] == query_post_id:
found_query = True
similar_posts = find_similar_posts(
query_content=post['content'],
current_post_id=post['id'],
post_data=post_data,
index=index,
k=3,
min_distance=0.1,
max_distance=0.8
)
result[post['id']] = {
'post_id': post['id'],
'post_title': post['title'],
'suggested_links': similar_posts
}
break
if not found_query:
logging.error(f"Query post ID {query_post_id} not found in post_data")
else:
logging.error("No FAISS index created; cannot find similar posts.")
# Display result
if result:
print(json.dumps(result, indent=4))
else:
print(f"Post ID {query_post_id} not found or no valid content.")What’s Happening:
- Fetch and Process: Calls fetch_posts to get all posts, then cleans and stores their data.
- Embeddings and Index: Builds a FAISS index with embeddings of all posts.
- Query: Finds the top three similar posts for the specified ID (e.g., 51724).
- Output: Produces JSON with the post’s details and similar posts.
- SEO Tip: The JSON format is developer-friendly, ideal for integrating into WordPress plugins for “automated related posts.”
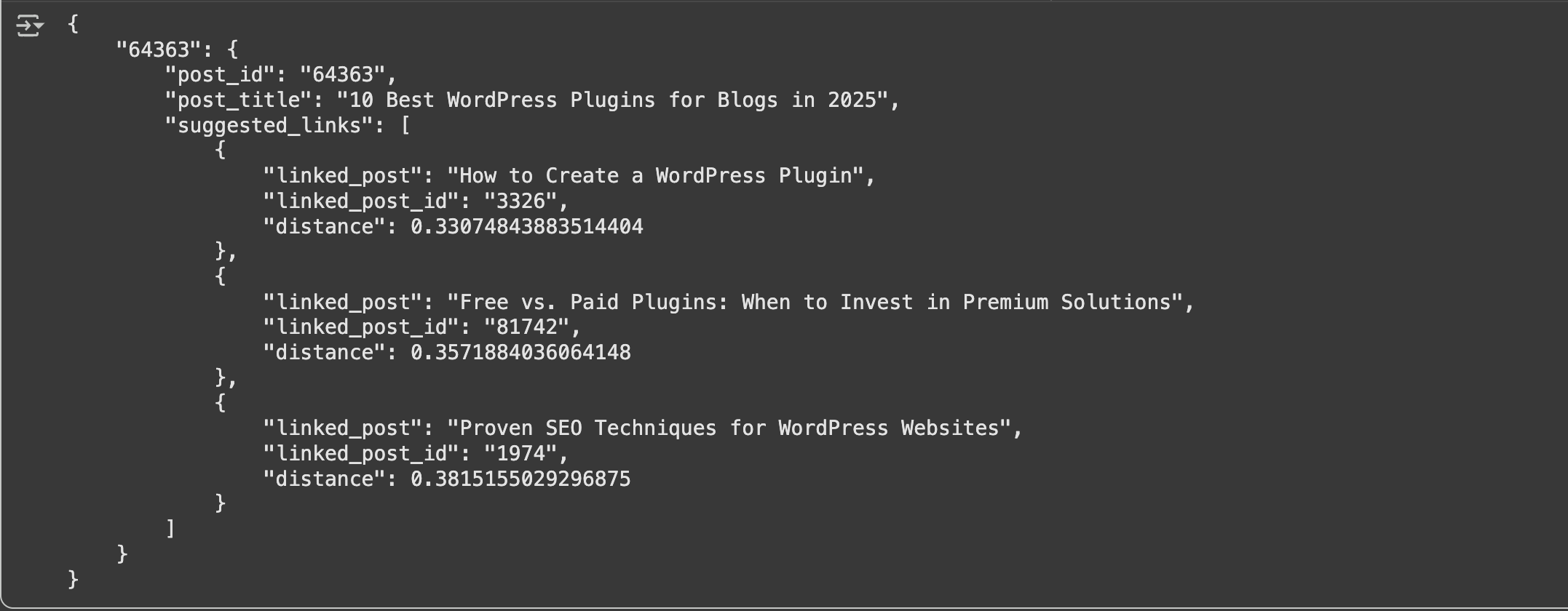
Understanding the Output
When you run this code, you’ll get results like:
Choosing Text for Comparison
You can compare different parts of a post to find similar posts:
- Full Content: Most comprehensive, capturing the entire post’s meaning (used by default).
- Title: Quick and topic-focused; uncomment cleaned_content = post_title.
- Summary/Excerpt: Use post.get(‘excerpt’, {}).get(‘rendered’, ”) for concise comparisons.
- First Paragraph: Often summarizes key points; uncomment the first paragraph code to extract it.
Each has pros and cons:
- Full Content: Best for accuracy but slower for large posts.
- Title: Fast but less detailed.
- First Paragraph/Summary: Balances speed and relevance.
Try swapping these in the script to see what works best for your site!
Final Thoughts
This isn’t just a “related posts” widget — it’s a semantic content discovery engine.
By understanding the true meaning behind your articles, it ensures every recommendation is contextually perfect.
Ready to try it?
Run the Colab notebook, test your own posts, and see how AI can transform the way your readers discover content.

Rupendra Choudhary is a passionate AI Engineer who transforms complex data into actionable solutions. With expertise in machine learning, deep learning, and natural language processing, he builds systems that automate processes, uncover insights, and enhance user experiences, solving real-world problems and helping companies harness the power of AI.