You finished building your AI agent. It passes all the tests, impresses everyone in the demo, and gets pushed to production. Then three weeks later, it starts giving inconsistent answers. A month after that, someone notices it is making decisions based on outdated assumptions. By month three, you are spending more time fire fighting than building.
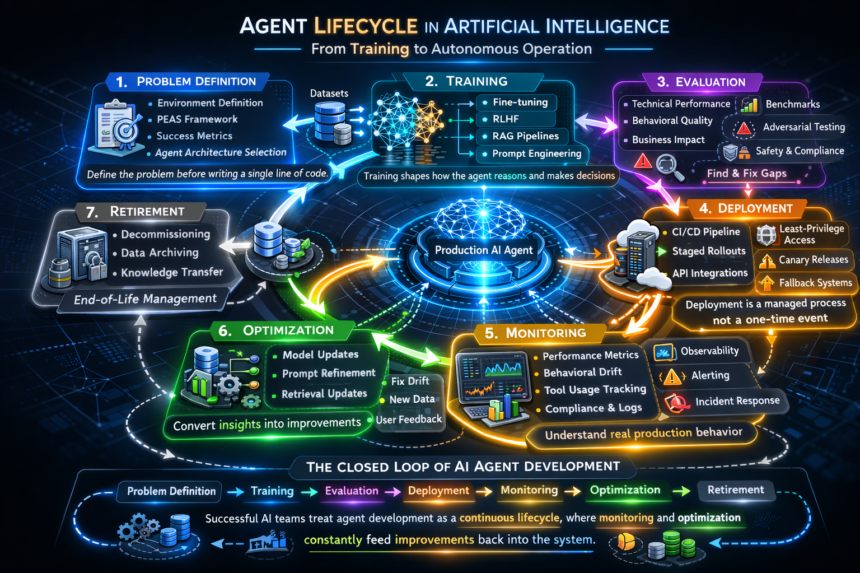
- Phase 1: Defining the Problem Before You Write a Single Line of Code
- Phase 2: Data Collection and Intelligent Agent Training
- Phase 3: Evaluation Is the Phase That Separates Good Teams From Great Ones
- Phase 4: Agent Deployment Is a Process, Not an Event
- Phase 5: Monitoring Is Where Production Reality Meets Your Assumptions
- Phase 6: Optimization Is the Loop That Determines Whether Your Agent Gets Better or Worse
- Phase 7: Retirement Is the Phase Nobody Plans For Until It Is Urgent
- Why the Lifecycle Matters More Than the Agent Itself
- The AI Agent Lifecycle at a Glance
- Conclusion
This is the most common story in AI agent development right now, and it almost always comes from the same root cause: treating deployment as the finish line rather than treating the AI agent lifecycle as an ongoing engineering discipline.
The global AI agents market was valued at USD 5.40 billion in 2024 and is projected to reach USD 50.31 billion by 2030, growing at a CAGR of 45.8%. With that growth comes real pressure to ship fast. But the teams actually extracting value are the ones who understand that shipping is only one phase, not the whole picture.
This guide walks through every phase of the AI agent lifecycle, with the practical depth that developers actually need.
Phase 1: Defining the Problem Before You Write a Single Line of Code
This phase sounds obvious. Most developers skip it anyway. The temptation to jump straight into model selection, framework choice, and architecture decisions is real because those things feel productive. Problem definition feels like a meeting.
But agents built without a rigorous discovery phase consistently automate the wrong work, amplify broken processes, or collapse under real-world variability. The EPAM research team behind the Agentic Development Lifecycle framework calls this Phase 0 for a reason: it comes before everything else.
During this phase you need to nail down a few things that will shape every decision that follows:
- What environment will the agent actually operate in? Which APIs can it call? What databases does it need to reach? What can it not touch?
- What does success look like in measurable terms? Not ‘improves customer support’ but ‘resolves tier-1 billing queries with an 85% resolution rate and under 3 seconds response time.’
- Where are the hard boundaries? Defining what an agent should never do is just as important as defining what it should do.
- Which agent architecture fits the task? If you are still getting a handle on the different types, Goal-Based, Utility-Based and Learning Agents: Practical Implementation Guide covers the practical tradeoffs in detail.
Working through the PEAS framework (Performance, Environment, Actuators, Sensors) at this stage is one of the most underrated moves a developer team can make. It forces the kind of structured thinking that saves painful rework later.
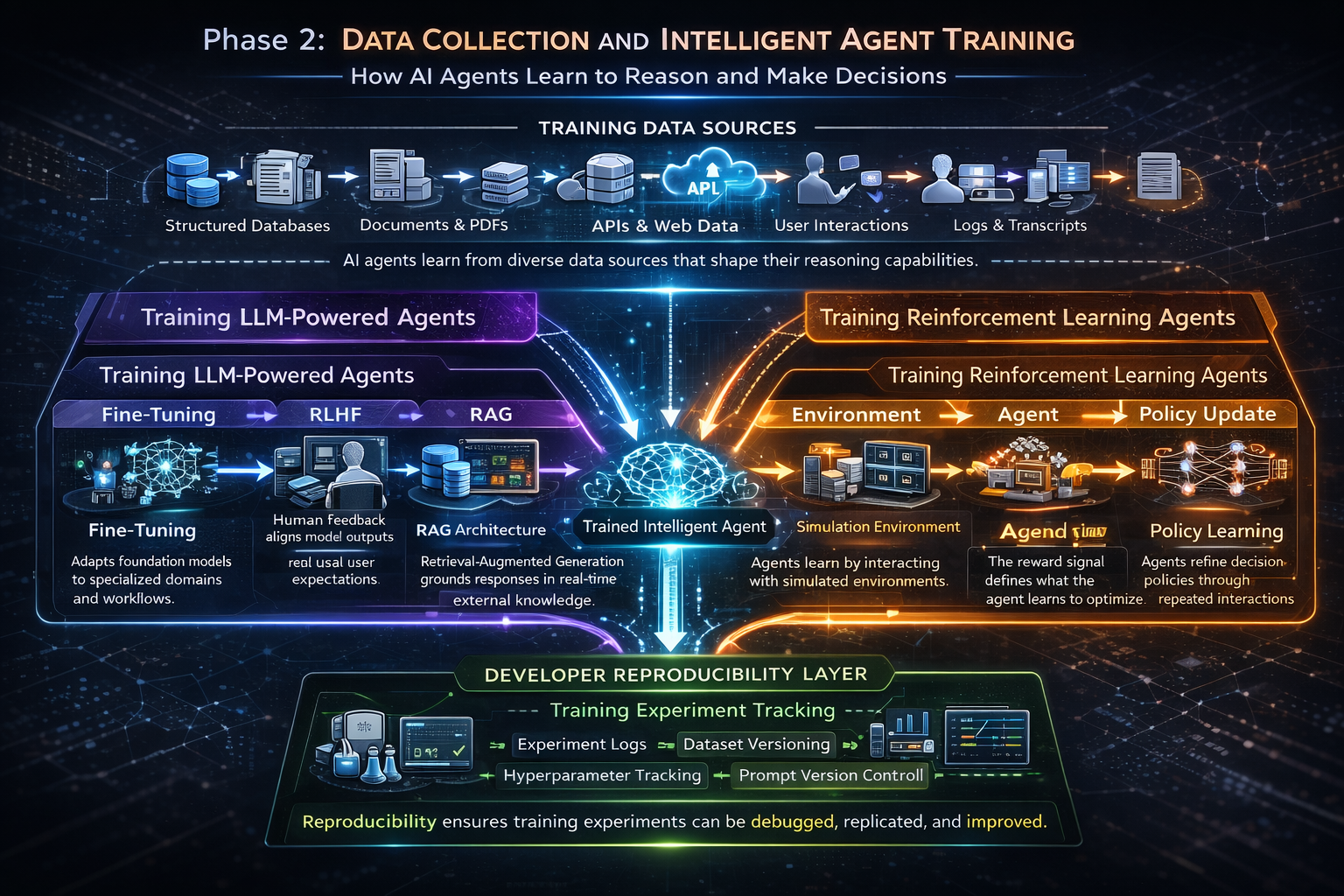
Phase 2: Data Collection and Intelligent Agent Training
Training is where you shape how an agent reasons and decides. The right approach here depends entirely on what kind of agent you are building.
For LLM-Backed Agents
Most production agents in 2026 are built on top of foundation models. You are almost certainly not training from scratch. Instead, you are choosing between a few approaches and possibly combining them:
- Fine-tuning on domain-specific data: This is the right move when your use case involves specialized vocabulary, specific workflows, or decision patterns that a general model gets consistently wrong.
- RLHF (Reinforcement Learning from Human Feedback): This is how you align outputs with real user expectations rather than just training data. The iterative feedback loop is what turns a generic LLM into an agent tuned for your specific context.
- RAG (Retrieval-Augmented Generation): When you need the agent to reason over live, external knowledge without retraining, RAG is the architectural pattern to reach for. It grounds the agent in current information at inference time.
- Prompt engineering and few-shot examples: For lighter-weight behavioral shaping where full fine-tuning is overkill, well-crafted prompts with representative examples can do a surprising amount of heavy lifting.
For Reinforcement Learning Agents
If you are building agents for robotics, trading systems, or game-playing scenarios, your training loop looks fundamentally different. Here you are designing reward functions, running simulations, and iterating until the agent learns generalizable policies. The reward signal design is where the real intellectual work happens, and a poorly designed reward function will produce an agent that games the metric rather than solving the actual problem.
Developer note: Whatever training approach you use, track everything obsessively. Datasets, hyperparameters, evaluation checkpoints, prompt versions. Reproducibility is what separates a recoverable incident from a mystery that eats three sprints.
Phase 3: Evaluation Is the Phase That Separates Good Teams From Great Ones
Evaluation is where the gap between what you built and what you actually need becomes visible. It is also the phase most teams rush, usually because there is pressure to ship and evaluation feels like it is delaying that.
That instinct is expensive. A poorly evaluated agent is a liability that will surface its problems in production, in front of users, at the worst possible time.
Strong evaluation works across three dimensions simultaneously:
- Technical performance covers your latency benchmarks, error rates, token costs, and task completion rates. These catch the obvious failures.
- Behavioral quality is harder to quantify but more important. Does the agent reason sensibly through edge cases? Does it fail gracefully or catastrophically when it encounters something outside its training distribution?
- Business alignment is the dimension teams forget most often. A technically correct agent that does not move the metrics you actually care about is still a failed project.
This is also the right time to stress-test your decision strategy. If you are unsure whether your agent should respond immediately to inputs or plan ahead before acting, the breakdown of reactive versus deliberative agents covers that architectural decision directly.
Do adversarial testing before you ship, not after. Prompt injection, malformed inputs, out-of-distribution scenarios, edge cases from real user behaviour. If you have not stress-tested for these in evaluation, you will encounter them in production.
Phase 4: Agent Deployment Is a Process, Not an Event
Deployment is commonly treated as a moment. Flip the switch, go live, and celebrate. In reality it is an ongoing managed process with specific decisions that have lasting consequences.
The technical fundamentals here overlap with traditional software engineering: containerization, CI/CD pipelines, environment configuration, API integration, access control. Most developers have solid instincts on these. But agent deployments carry some considerations that are genuinely different:
- Least-privilege access is non-negotiable. Agents that can call APIs, query databases, or trigger workflows are attack surfaces for every tool they can reach. Scope permissions to exactly what the agent needs and nothing more.
- Staged rollouts save you from yourself. Canary deployments catch behavioral regressions before they become customer-facing problems. Do not send 100% of traffic to a new agent version on day one.
- Fallback paths need to be defined before you need them. What happens when the agent fails? What happens when it produces an unexpected output? Graceful degradation has to be designed in, not bolted on later.
- Version control the entire definition. The agent’s prompts, tools, model version, and configuration all need to be captured together in source control. Rollbacks require this. Debugging requires this.
If you are still choosing your deployment infrastructure, the comparison of top agentic AI frameworks in 2026 covers LangGraph, CrewAI, AutoGen, and others with production deployments specifically in mind.
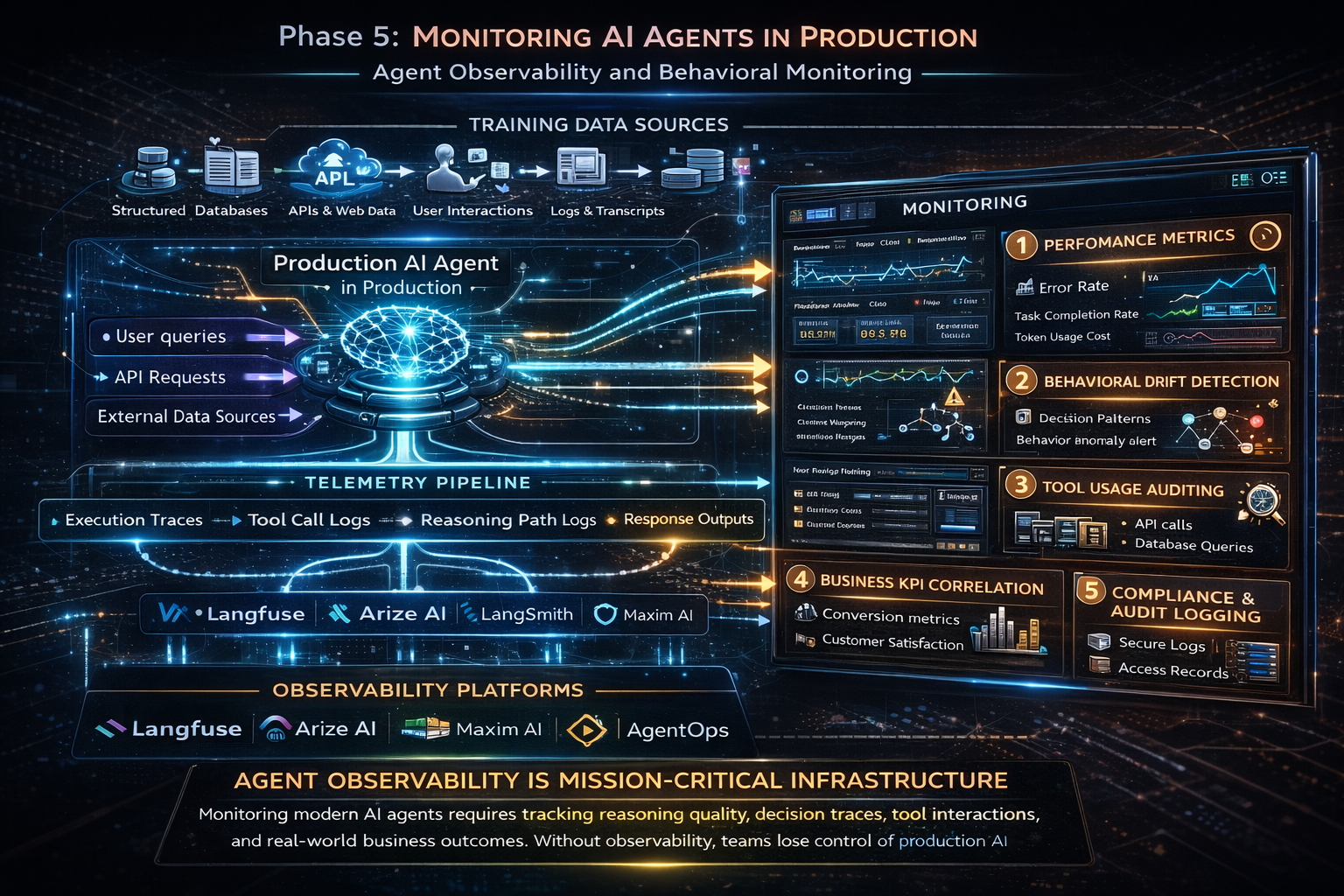
Phase 5: Monitoring Is Where Production Reality Meets Your Assumptions
Here is something worth really internalizing: a deployed AI agent is never done. The environment it operates in keeps changing. User behaviour shifts. Data distributions drift. Edge cases accumulate. Over 80% of organizations have encountered risky or unexpected behaviours from deployed AI agents according to McKinsey research. Most of those surprises happen after deployment, not before.
Monitoring an agent is fundamentally different from monitoring a traditional API. You are not just tracking uptime and latency. You are tracking reasoning quality, and that requires a different category of tooling.
What Agent Observability Actually Looks Like
The observability space for AI agents matured significantly through 2025. Platforms like Langfuse, Arize AI, LangSmith, and Maxim AI now offer distributed tracing across full agent execution paths, from user input through tool calls all the way to the final response.
In practical benchmarking of these tools running 100 identical queries on a multi-agent workflow, AgentOps introduced roughly 12% latency overhead while Langfuse came in around 15%. These are acceptable tradeoffs for the depth of visibility they provide, but worth knowing when you are sizing your infrastructure.
What you need to be tracking in production goes beyond the basics:
- Performance metrics (response time, error rates, task completion) catch obvious failures early.
- Behavioral drift detection tells you when the agent’s decision patterns start diverging from what you validated, even when no code has changed.
- Tool usage auditing shows you which tools the agent is calling, at what frequency, and with what parameters. Unexpected tool call patterns are often the first signal of a problem.
- Business KPI correlation connects your technical metrics to actual outcomes. This is how you know whether the agent is creating value, not just running.
- Compliance and audit logging is critical in regulated industries like finance and healthcare, where you may need to reconstruct exactly what an agent decided and why.
In 2026, AI agent observability has moved from a developer convenience to mission-critical infrastructure. If you cannot answer ‘why did it give that response’ and ‘how much did that cost’ quickly for any production agent call, you have already lost control of the system.
Phase 6: Optimization Is the Loop That Determines Whether Your Agent Gets Better or Worse
Optimization is what converts your monitoring data into actual improvements. This loop is the difference between an agent that slowly degrades over months and one that becomes measurably more capable and reliable over time.
The triggers that should kick off an optimization cycle are not always obvious. Some are data-driven. Others come from user feedback. A few come from external events entirely outside the system:
- Model drift detected: Retrain or fine-tune on recent interaction data. The fraud detection agent that was trained on last year’s transaction patterns will struggle with new fraud schemes.
- New edge cases discovered: Expand test coverage, update prompts, refresh your retrieval sources.
- User behaviour shift: Revisit goal definitions and success metrics. What made sense six months ago may not reflect what users actually need today.
- Performance regression: Roll back to the previous version, run root-cause analysis, ship a targeted fix rather than a broad update.
The architectural decision that makes optimization sustainable is modularity. If your agent’s LLM backbone, retrieval layer, tool integrations, and memory system are cleanly separated, you can update each independently. This is especially relevant for autonomous agent systems where decisions cascade across complex multi-step workflows.
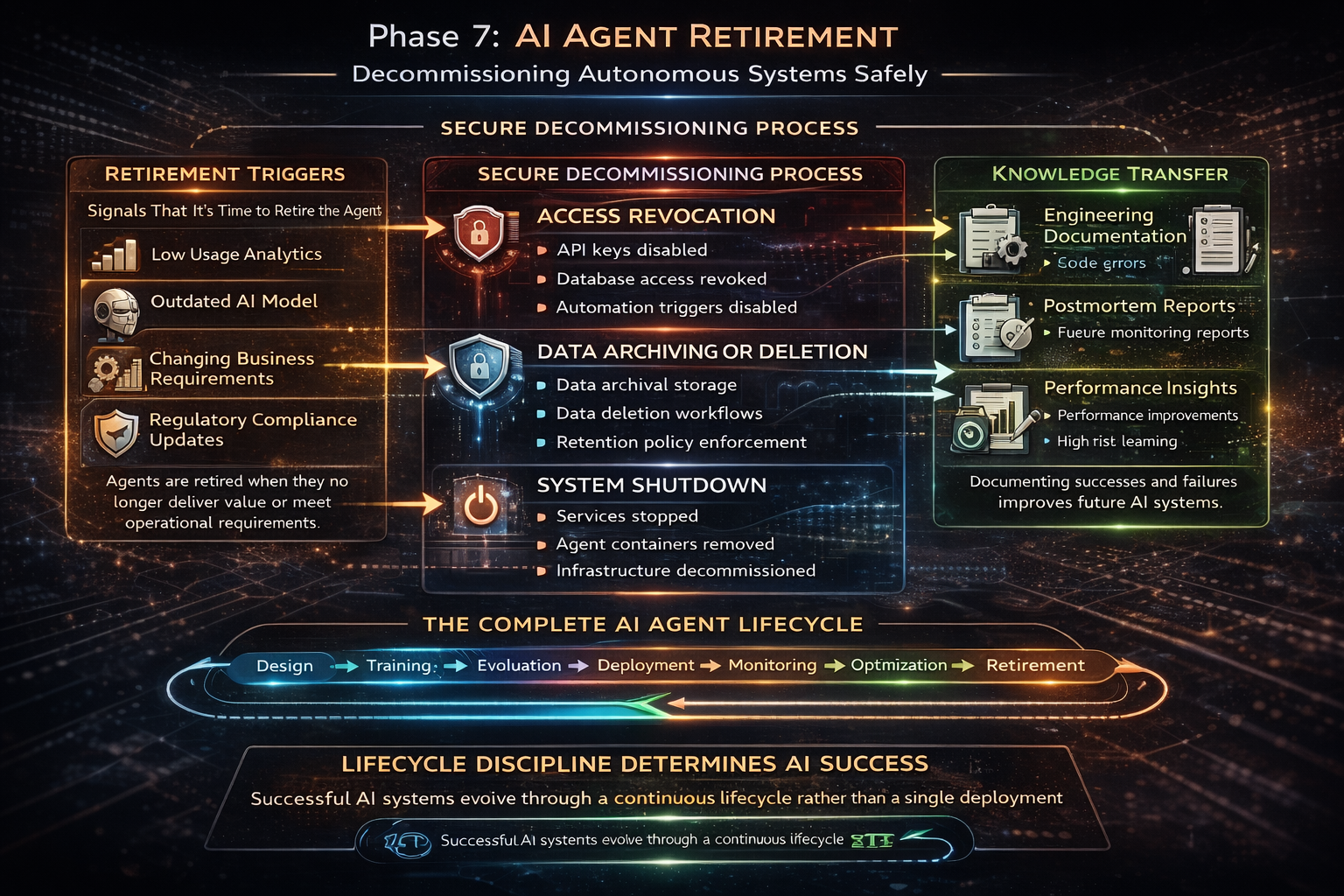
Phase 7: Retirement Is the Phase Nobody Plans For Until It Is Urgent
Agents do not run forever. A combination of low usage, model obsolescence, shifting business requirements, or regulatory changes will eventually signal that it is time to decommission an agent. Planning for this from day one is a sign of engineering maturity. Reactive decommissioning is messy and leaves security loose ends.
Retirement done properly means revoking all access and permissions (do not leave ghost agents with lingering system access), archiving or deleting data according to your retention policy, and documenting what the agent did, what worked, and what failed. That documentation shapes the next agent you build.
Why the Lifecycle Matters More Than the Agent Itself
According to research across enterprise AI deployments, 42% of companies dropped most of their AI initiatives in 2025, and more than 80% of AI initiatives in finance failed to deliver meaningful production value or stalled before scaling. The common thread across these failures is not bad models or wrong frameworks. It is treating agent development as a one-time build rather than a continuous lifecycle.
The teams that scaled successfully are the ones who implemented what practitioners now call a closed operating loop: development, evaluation, deployment, and real-world feedback feeding back into development. Each phase informs the next. The agent improves instead of drifting.
Understanding where your agent sits architecturally matters for how you approach this loop. Whether you are working with a simple reactive agent or a more sophisticated cognitive system affects your monitoring priorities, your optimization cycles, and how much runway you have before drift becomes a real problem.
The AI Agent Lifecycle at a Glance
- Phase 1: Design Problem framing, PEAS definition, agent type selection, stakeholder alignment
- Phase 2: Training Data collection, fine-tuning, RLHF, RAG setup, reward function design
- Phase 3: Evaluation Technical benchmarks, behavioral testing, adversarial probing, KPI alignment
- Phase 4: Deployment CI/CD pipelines, staged rollout, access control, fallback paths, version control
- Phase 5: Monitoring Performance metrics, behavioral drift, tool auditing, compliance logging
- Phase 6: Optimization Retraining, prompt iteration, modular updates, root-cause analysis
- Phase 7: Retirement Access revocation, data archival, documentation for the next build
Conclusion
The developers who build reliable production agents are not necessarily the ones with the deepest ML knowledge. They are the ones who treat agent development as a systems engineering discipline: rigorous at each phase, honest about what monitoring is telling them, and disciplined about the continuous loop of improvement.
Build in phases. Monitor like your reputation depends on it. Optimize continuously. Plan for retirement before you ever go live.
If you are still grounding yourself in the fundamentals, What Is an Intelligent Agent in AI? Types, Architecture and Real Examples is the right starting point before diving into lifecycle management in depth.

Hi, I’m Pragya.
I write about AI tools, digital trends, and emerging technologies in a way that’s simple, practical, and easy to apply. I enjoy exploring new AI platforms, testing their features, and breaking them down into clear guides that actually help people use them confidently.
My focus is not just on writing content, but on creating value. I believe powerful technology should feel accessible, not overwhelming. That’s why I aim to turn complex tools into actionable insights for creators, marketers, and growing online businesses.
I’m constantly learning, researching, and staying updated with the fast-moving AI space so readers always get relevant and useful information.




