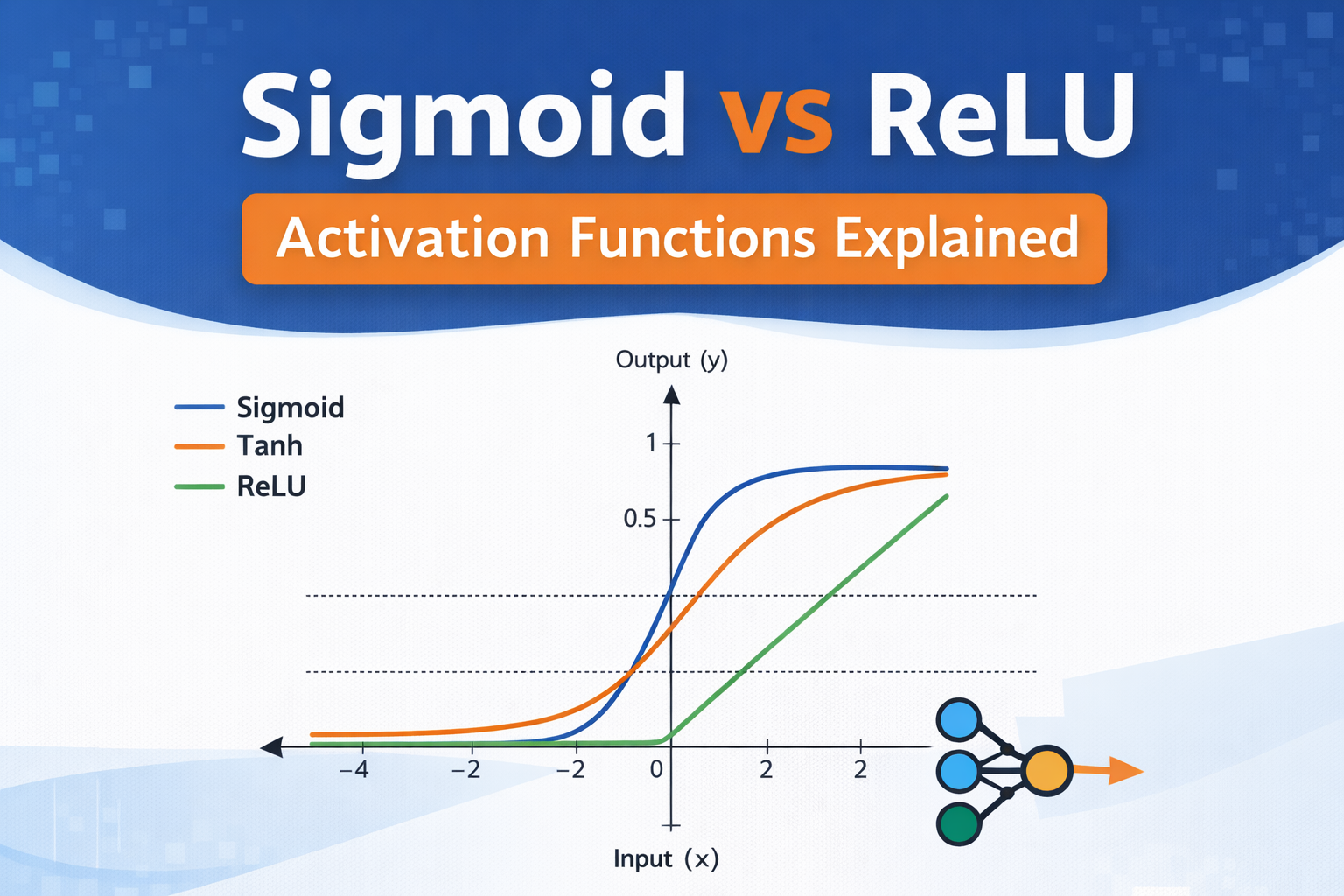
Sigmoid vs ReLU is one of the most important comparisons in deep learning. Sigmoid limits outputs between 0 and 1 and often slows training due to vanishing gradients, while ReLU allows faster learning and better performance in modern neural networks.
Sigmoid vs ReLU is a common question for anyone learning deep learning or neural networks. These activation functions decide how a model learns patterns, how fast it trains, and how accurate it becomes. Choosing the wrong activation function can slow learning or even break a deep neural network.
Before diving deeper, it helps to understand what is deep learning and how neural networks work. Activation functions sit at the heart of every neural network and directly affect model performance.
Sigmoid vs ReLU: What Are Activation Functions?
Activation functions decide whether a neuron should activate or stay silent. They introduce non-linearity into neural networks, allowing models to learn complex relationships. Without them, deep learning models would behave like simple linear equations.
In the sigmoid vs ReLU debate, the main difference lies in how each function processes inputs and gradients during training.
What Is the Sigmoid Activation Function?
The sigmoid activation function converts input values into outputs between 0 and 1. Because of this range, sigmoid was widely used in early neural networks, especially for binary classification tasks.
Key features of sigmoid include:
- Smooth and continuous curve
- Output range between 0 and 1
- Easy interpretation as probability
However, sigmoid has a major drawback. For very large or very small inputs, gradients become extremely small. This issue, known as the vanishing gradient problem, makes training deep networks slow and unstable.
What Is the ReLU Activation Function?
ReLU, or Rectified Linear Unit, outputs zero for negative inputs and returns the input value for positive numbers. This simple behavior makes ReLU computationally efficient and easy to optimize.
Key benefits of ReLU include:
- Faster training speed
- Reduced vanishing gradient problem
- Better performance in deep networks
According to TensorFlow activation function documentation, ReLU is the default activation function for most modern deep learning models.
Sigmoid vs ReLU: Key Differences Explained
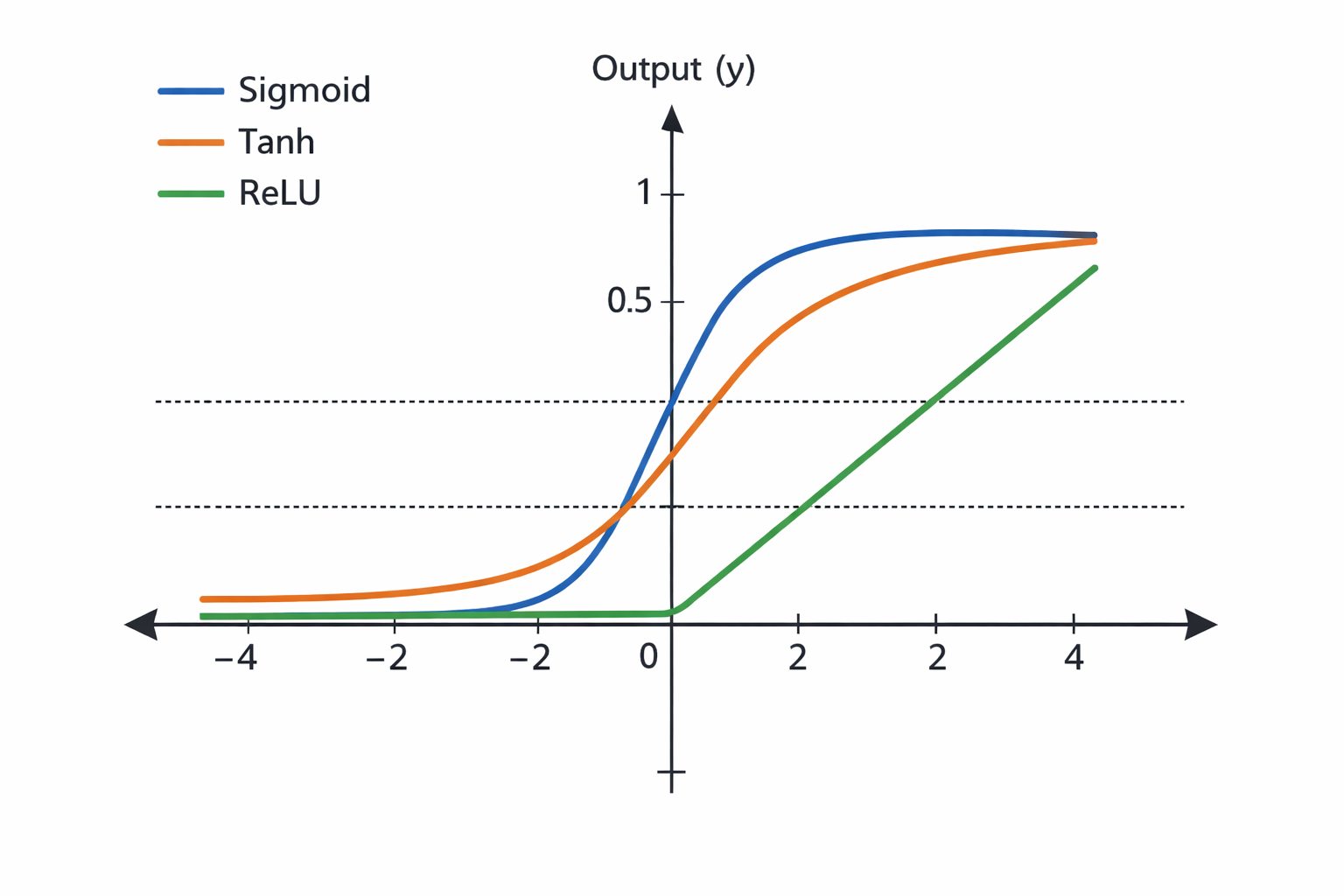
When comparing sigmoid vs ReLU, the differences become clear during training and performance evaluation.
- Training Speed: ReLU trains much faster than sigmoid.
- Gradient Behavior: Sigmoid suffers from vanishing gradients, while ReLU largely avoids it.
- Output Range: Sigmoid outputs between 0 and 1; ReLU outputs zero or positive values.
- Use Cases: Sigmoid works best for output layers in binary classification, while ReLU dominates hidden layers.
Why Is Sigmoid Not Used Anymore?
Sigmoid is not completely obsolete, but it is rarely used in hidden layers today. The vanishing gradient problem slows learning as networks grow deeper. Modern architectures favor ReLU because it allows gradients to flow more freely.
Google also highlights this limitation in its machine learning documentation.
Sigmoid vs ReLU vs Tanh
Many learners also compare sigmoid, tanh, and ReLU. Tanh outputs values between -1 and 1 and performs better than sigmoid in some cases. Still, ReLU usually wins due to simplicity and speed.
When Should You Use Sigmoid vs ReLU?
Choosing between sigmoid vs ReLU depends on the layer and task.
- Use sigmoid in the output layer for binary classification
- Use ReLU in hidden layers for deep neural networks
- Avoid sigmoid in deep hidden layers
If you are building modern AI systems, ReLU should be your default choice unless you have a strong reason to use sigmoid.
Frequently Asked Questions
Is ReLU always better than sigmoid?
ReLU performs better in most deep learning models, but sigmoid still works well for binary output layers.
Can sigmoid and ReLU be used together?
Yes. Many models use ReLU in hidden layers and sigmoid in the final output layer.
Which activation function is best for beginners?
ReLU is easier to understand, faster to train, and more forgiving, making it ideal for beginners.
Final Thoughts on Sigmoid vs ReLU
The sigmoid vs ReLU comparison clearly shows why deep learning has evolved. Sigmoid played an important role in early neural networks, but ReLU unlocked faster training and deeper architectures. If you want better performance, quicker results, and modern best practices, ReLU is the clear winner.

Sandeep Kumar is the Founder & CEO of Aitude, a leading AI tools, research, and tutorial platform dedicated to empowering learners, researchers, and innovators. Under his leadership, Aitude has become a go-to resource for those seeking the latest in artificial intelligence, machine learning, computer vision, and development strategies.